| Statistical models, like
Regression, Logistic, or CHAID analyses can be highly useful
tools. But all to often these tools are thoughtlessly applied
in what amounts to the blind statistical processing of data.
The primary characteristics of blind statistical processing
are: underlying assumptions are ignored, modeling is performed
with no reference to its embedding context, associations among
predictors are ignored, and an emphasis on predictive utility
(e.g., R Square) as the primary indicator of the quality of
the resultant mathematical representation.
Furthermore, these perils are often
not readily apparent because in many situations there is an
organizational separation of research, interpretative, and
statistical responsibilities. The separation of these logically
integrated components in the modeling process is inherently
dangerous because it often leads to a “blind leading
the blind” situation.
In the statistics business, it’s
common practice to build predictive models using large lists
of predictor variables with little to no thought expended
on the nature of the associations among the predictors. The
resultant quality of these models are solely defined in terms
of their predictive utility. The fact that the set of predictor
variables are often substantially intercorrelated is usually
ignored with reasoning along the lines that if predictive
utility is substantial, then any violation of assumptions
can be safely ignored. After all, “the model does a good
job of predicting the dependent variable.”
While violations of basic assumptions
often have serious technical consequences, the examination
of data without consideration of its embedding context runs
the considerable risk of building an under conceptualized
model. Under conceptualized models are particularly dangerous
when they are accompanied with moderate to high predictive
utility. In reality, predictive utility and enhanced understanding
are not necessarily congruent.
In Part One of this paper, we provide
an example of the dangers of under conceptualization with
a simple, one predictor variable model. In Part Two we will
examine more closely the dangers of under conceptualization
in conjunction with intercorrelated predictor variables.
Part I – The
Under Conceptualized Simple Model
This example is from the fast food industry. Management’s
question was how does speed of the foods delivery (after the
order was made) affect overall customer satisfaction. One
way of approaching this is to perform a regression analysis
where ratings on food 'delivery speed 'predict overall customer
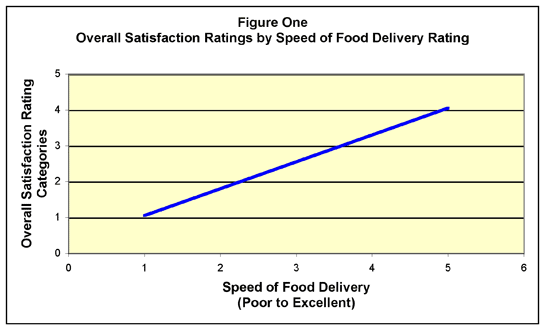
satisfaction (Figure One). As can be seen, there is a substantial
linear association (R Square 60 %) between ratings of speed
of food delivery (after the order ), and overall customer
satisfaction.
Acting on this information,
Management might consider embarking on an expensive re-engineering
program where food delivery speed is enhanced through thousands
of retail outlets. After all, according to Figure One, the
faster the food delivery, the higher the customer’s satisfaction,
and higher levels of customer satisfaction usually lead to
more business.
In the model of Figure One, food delivery
performance ratings are measured on a Likert type scale where
a “one” means poor, and a “five” means
excellent. The resultant model suggests that increases in
customer satisfaction will occur if the food is delivered
faster, but how much faster? We can see that the current average
food deliver speed rating (the ‘x’ axis) is around
4.2, but you can’t build an “operationally defined”
delivery process in terms of subjective performance ratings.
You need to provide guidance in terms of elapsed time not
satisfaction with time.
To accomplish that, we need to “map”
actual food delivery speed against overall satisfaction ratings
(Figure Two). Of course, in order to do this, you have to
anticipate the need for food delivery times in the survey
design phase. Recognition of the latter point demonstrates
one of the dangers of separating research, interpretative/
analytical and statistical responsibilities when performing
data analysis.
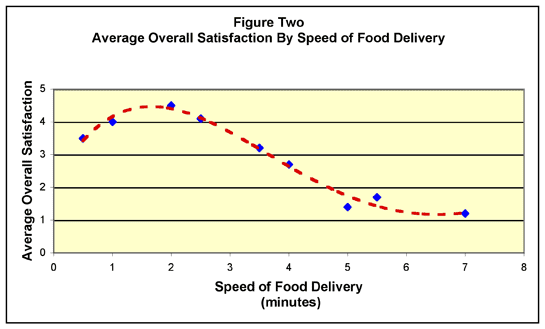
When we examine Figure Two, we encounter
two surprises. First, the form of the association between
food delivery speed in minutes and overall satisfaction is
not linear. For food delivery times between 8 and about 1.8
minutes, the form of the association is “S” shaped.
More importantly, as food delivery times exceed 1.8 minutes
the nature of the association changes from positive to negative.
In other words, there is such a thing as “too fast”
fast food!
Results from the blind
statistical processing approach implied that the gross form
of the association between customer satisfaction and faster
food delivery ratings is strictly linear. However, the blind
statistical approach failed to identify the distinct non linearity’s
occurring at the upper and lower ranges of food delivery times.
The application of a more rigorous
statistical approach that included an examination of “Residuals”
in the linear model of Figure One would have suggested caution
because the variability of ratings of satisfaction with food
delivery speed were larger at high rating values. However,
that point could be stated for almost any regression equation
because variability usually increases with higher rating values.
Actually, for the underlying model of Figure One, no amount
of statistical work would be able to coax the true nature
of the non linearity underlying the data because the wrong
question was asked.
Subjective satisfaction ratings on food delivery time tell
you how satisfied customers are with the food delivery time,
but they don’t provide any information on the food delivery
times necessary to produce those ratings.
The fact that the predictive model
represented in Figure One is under conceptualized becomes
apparent when past a certain point, faster food delivery results
in decreases in customer satisfaction. That finding suggests
the presence of an interaction. An interaction occurs when
the association between two variables varies as a function
of other factors.
The primary flaw with the Figure One
model is not statistical in nature, the problem is the model
is under conceptualized. The simple linear model of Figure
One states there is no limit to the benefits of faster and
faster food delivery times. However, the “S” shaped
curve in Figure Two suggests that the benefits of faster and
faster food delivery times decrease as food delivery times
get faster, and most importantly, past some critical point,
faster delivery times actually result in lower levels of overall
customer satisfaction.
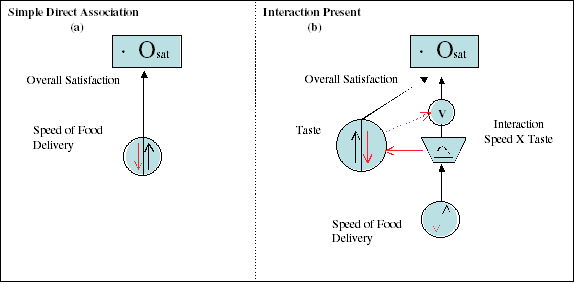
Figure Three provides two conceptual schematic representations.
The first diagram “Simple Direct Association” shown
in panel “a” provides the conceptual schematic for
the simple regression model, results of which are demonstrated
in Figure One.
Figure
Three
|
According to that conceptual
model, there is a direct association between food delivery
speed and overall satisfaction. Now examine the conceptualization
in panel “b”. This conceptualization also states
there is a direct association of food delivery speed with
overall satisfaction. However, we know from Figure Two that
when food delivery time exceeds a critical point, some mechanism
acts to decrease the customers overall satisfaction.
How would something like that work?
Well, it takes time to cook food-to-order (cooking time).
If you deliver food faster than the needed cooking time, that
means you are pre-cooking (e.g., pre-staging) the food. Pre-cooked
food often does not taste as good as cooked-to-order food.
This suggests that food delivery speed and taste can interact.
The only way to get the food to a customer faster than the
cooking time is to pre-cook the food. Once you start pre-cooking
the food, two things happen. First, taste satisfaction drops.
Second, as taste satisfaction drops, the positive relationship
between food delivery speed and overall customer satisfaction
is reduced. This is a directly testable hypotheses, and in
fact this conceptualization does an excellent job of explaining
the pattern of obtained results.
The nature of the associations described
above are demonstrated in panel “b” of Figure Three
which is a specialized form of a “causal loop diagram.”
The “rate converter” symbol directly above the speed
of food delivery variable contains a version of the form of
the function that appears in Figure Two. What this symbolizes
is that the association between speed of food delivery is
direct until the point where the function turns from a positive
to a negative association. When that critical time is reached,
further decreases in food delivery times drive perceived ratings
of taste lower. That is signified by the red arrow from the
rate converter to taste satisfaction ratings.
Now notice the red arrow from taste
satisfaction ratings to the “V” symbol. The “V”
symbol stands for “Valve.” When food delivery speed
starts to inhibit taste satisfaction ratings it also ceases
to provide any further enhancements in overall customer satisfaction
derived from faster food delivery. So the interaction is reciprocal
in nature. Basically, food delivery speeds lower than the
food’s cooking time results in decreased taste satisfaction.
Decreased taste simultaneously inhibits the positive association
between food delivery speed and overall customer satisfaction.
This conceptual model reveals the foundation
for the “Have it your way” marketing campaign. In
addition, once you understand what is happening in the model
demonstrated in Figure Three, panel “b”, it naturally
leads to product specific hypotheses.
You might think that a “limiting”
model of this nature is industry specific, but in fact, this
type of limiting association is quite common. For example,
consider retail sales. Overall customer satisfaction typically
increases as a function of the available selection of merchandise
on the selling floor. However, past a certain point, further
increases of merchandise on the selling floor results in a
disorganized mess. At that point, organization, ease of finding
what you are looking for, and cleanliness ratings start to
drop. This in turn inhibits the normally positive association
between customer satisfaction and greater selection of merchandise.
Summary:
In Part One of this paper we have demonstrated that the blind
statistical processing of data, in conjunction with a high
degree of predictive utility, is particularly dangerous because
it provides the illusion of understanding when in fact, the
underlying model could be seriously under conceptualized.
The primary result of any modeling effort should be focused
on a better understanding of how the system works, not the
models predictive utility which is likely to be mostly influenced
by the larger proportion of data away from obvious boundary
conditions.
To a scientist, the notion that someone
who knows how to run statistical software is going to provide
critical insights on mechanisms responsible for something
as complex as “global warming” is ridiculous. Its
ridiculous because the statistical technician possess no contextual
knowledge, and knows little to nothing about underlying mechanisms.
Yet, the blind statistical processing of data remains the
norm in the business community where the complexity of the
underlying associations are equally impressive.
Statistical algorithms seek to maximize
explained variation. Explained variation is not equivalent
to understanding. Contextual knowledge is essential in the
process of understanding. There are no algorithms that create
understanding, there is no substitute for contextual knowledge.
The creation of understanding requires careful thought.
To paraphrase Louis Pasteur: the recognition
of relevance favors the prepared mind.
|